An intro to comm and diff commands
It's often useful to compare versions of text files.
It's often useful to compare versions of text files. Let's take a look at comm and diff
The comm command
This command compares two text files and displays the lines that are unique to each one and the lines they have in common.
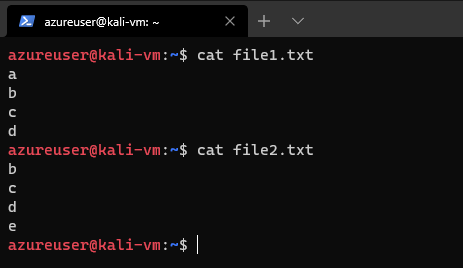
Let's say we have these two files:
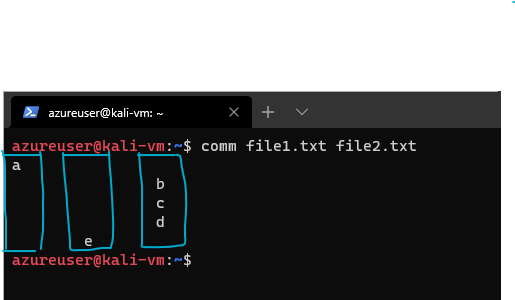
When we run comm file1.txt file2.txt we get
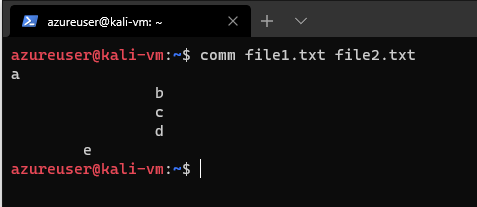
In my opinion, the comm output is somewhat hard to look at, but it's three columns. Excuse my terrible lines:
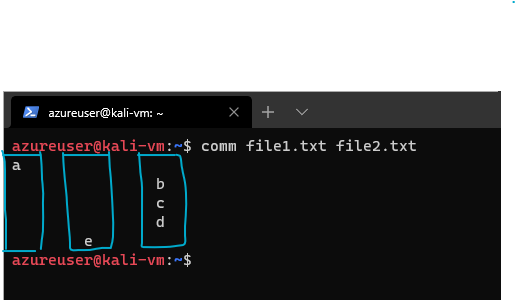
The first column contains lines unique to the first file argument, the second column contains the lines unique to the second file argument, and the third column contains the lines shared by both files.
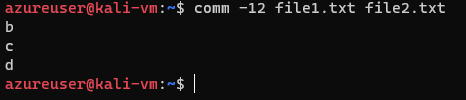
We can choose to suppress a specific column by using the option -n where n is either 1, 2, or 3. Say we wanted to output only the lines shared by both files, we can use comm -12 file1.txt file2.txt
The diff command
diff is a much more complex tool. It supports many output formats and has the ability to process large collections of text files at once. diff is often used to create diff files (patches) that are used by programs such as path to convert one version of a file or files to another version. Let's run diff on our same two files from before diff file1.txt file2.txt
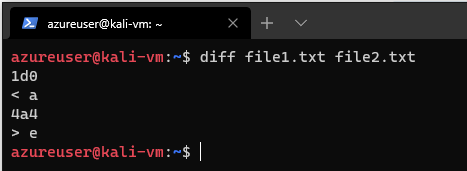
This is the default style output, in this format, each group of changes is preceded by a change command in the form of range operation range to describe the positions and types of changes required to convert the first file to the second file.
First we see
1d0
< aThis is telling us that we have to delete the first row in the file1, which is the line with a.
Next we have
4a4
> ewhich is telling us that we have to add a line to the first file, in the fourth line position, then it tells us which line to add > e
I know this is confusing, to be fair, the default style isn't used as much as the context format and unified format are, let's look at those an explain more.
We can use the context format by adding the -c option
diff -c file1.txt file2.txt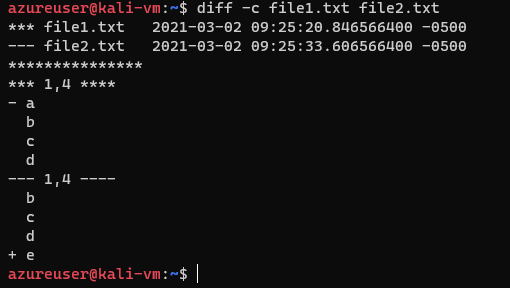
At the top we see the names of the two files and their timestamps, the first file is marked with asterisks, and the second file is marked with dashes. diff will use either asterisks or dashes to let us know which file it's talking about throughout the remainder of the listing.
Next we see a line of asterisks which is just formatting.
Then we've got groups of changes, in the first group we see
*** 1,4 ****
which means lines 1 through 4 in the first file
and then we see
- a
b
c
dWhich is the contents of the file, except there's a - before the a, that means we have to remove it.
| Indicator | Meaning |
|---|---|
| blank | No change needs to be made |
| (-) | Line needs to be deleted |
| (+) | Line needs to be added |
| ! | Line needs to be changed |
In our first group, we can see that the line with - a needs to be removed from our first file. Our second group of changes is
--- 1,4 ----
b
c
d
+ ethe ---1,4---- is the range of the second file, the + e means we need to add this line to the first file, remember the goal is to make the first file match the second file.
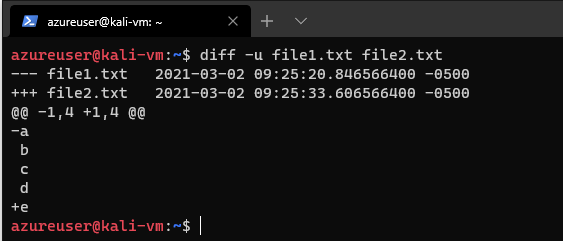
We can also use the unified format it's similar, but more concise, it eliminates the duplicated lines of context. diff -u file1.txt file2.txt